Integrating secret hygiene into AI and ML workflows
As AI becomes increasingly integrated into business workflows, organizations are leveraging private large language models (LLMs) to automate tasks, extract insights, and streamline operations. This shift brings with it a growing reliance on sensitive and proprietary data, fueling both innovation and new security risks.
One of the most overlooked threats in this new landscape is the presence of secrets embedded in the data used to train or interact with AI models. These secrets can be inadvertently exposed during model training or inference, potentially leaking access to critical systems.
This blog will explore how organizations can protect themselves while embracing the power of AI.
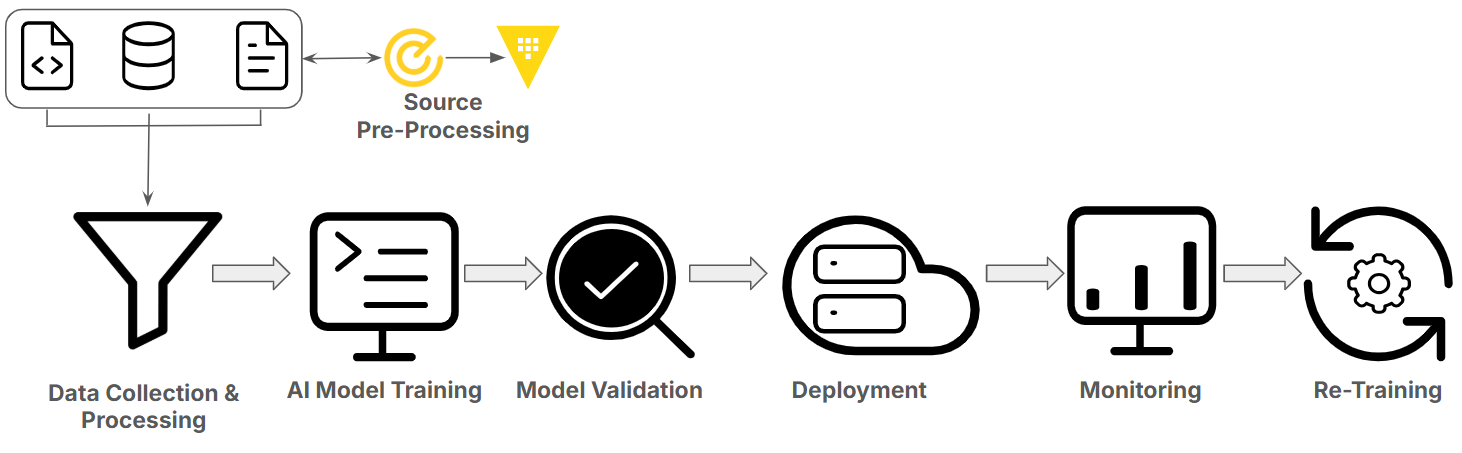
AI model training process
To understand how secrets end up in AI models, it helps to look at how these systems are built. The typical lifecycle of an AI model involves several key stages, each presenting unique opportunities for sensitive data to be exposed.
Data collection
The learning journey begins with large-scale data collection. For language models, this typically includes billions of text samples, anything from books and websites to technical documents and support chats. The model doesn't "know" what's important; it learns from whatever it's given. If the data includes passwords, keys, or proprietary information, that content becomes part of the model's knowledge base.
Tokenization
Next, the data is tokenized or broken into smaller units like words or subwords that the model can process. This step converts human-readable text into numerical representations but doesn’t abstract or filter meaning. Sensitive information, once tokenized, still carries its structure and value, just in a form the model can learn from.
Training
During training, the model ingests vast amounts of tokenized data to learn statistical relationships between words, phrases, and patterns. The goal is to predict the next token in a sequence. However, in doing so, the model may "memorize" parts of the data that appear frequently or follow consistent patterns.
Fine-tuning
Fine-tuning further adapts a pretrained model to specific tasks or domains using more focused datasets. This step improves performance but also narrows the model’s attention to whatever is in the fine-tuning set. If that data contains recurring or sensitive strings, the model is even more likely to internalize and potentially surface them in output.
Inference and prompting risks
Training may be complete, but the risks don’t end there. When models are deployed and exposed to user inputs during inference, such as queries in a chatbot or API, they generate responses based on their learned parameters and the immediate prompt context.
Parameterization: What the model actually learns
During training, the model adjusts billions (or trillions) of internal values called parameters. These parameters define how the model interprets relationships between tokens — essentially forming its understanding of language, logic, and context.
The model doesn’t store raw data, but it can learn strong associations or patterns, especially if they appear frequently or follow a predictable format. This is where the risk lies: if a secret is included in the training data, the model may adjust its parameters in a way that makes it possible to regenerate or infer that key when prompted in the right way.
Even though the model isn’t "copying and pasting," these learned parameters can reflect sensitive patterns so well that secrets are functionally retrievable. Look into the confused deputy problem for further examples of how chatbots and AI agents can be tricked into revealing sensitive information.
Where secrets leak into AI pipelines
Secrets can slip into AI pipelines from a variety of sources. Understanding these common leak points is critical for effective secrets management.
- Code repositories: Hard-coded secrets sometimes remain in source code. If this code is included in training datasets, the model can inadvertently learn these secrets.
- Logs and monitoring: Application logs, error reports, and monitoring dashboards can capture sensitive details like session tokens or personally identifiable information (PII). When logs are ingested without filtering, these secrets become part of the training data.
- Internal communications: Help desk tickets, and customer support transcripts often contain sensitive credentials or private information. Feeding these documents into training or fine-tuning processes risks exposing confidential data.
- Documentation: Wiki pages, design docs, runbooks, and knowledge bases may include embedded credentials, service account details, or encryption keys.
- Notebook environments: Interactive coding environments such as Jupyter notebooks or Google Colab are popular for experimentation but can contain embedded secrets in configuration cells, environment variables, or inline code.
Identifying and securing these hidden secret repositories is a foundational step toward safe and responsible AI model development.
Impacts of secrets exposure in AI
When secrets find their way into AI models, the consequences can be severe and long-lasting. Unlike traditional data breaches, where compromised credentials can be revoked and replaced relatively quickly, secrets embedded within AI systems pose a persistent threat.
- Irremovable secrets: Once a secret is learned and encoded into a model’s parameters, it becomes extremely difficult, if not impossible, to remove. Unlike deleting a file or revoking access, extracting or sanitizing a trained model requires complex, resource-intensive processes and may not guarantee complete eradication.
- Costly mitigation: Responding to secret leaks often means rotating credentials across all affected systems, which can disrupt business operations and introduce downtime. In some cases, organizations must retrain or fine-tune models from scratch using sanitized datasets — a process that demands substantial compute resources, time, and cost.
- Legal, regulatory, and reputational risks: Exposure of sensitive data through AI systems can trigger compliance violations under regulations, or industry-specific standards. Beyond legal penalties, public leaks can severely damage customer trust and an organization’s brand reputation, impacting business continuity and growth.
HCP Vault Radar helps eliminate secrets
One of the biggest challenges in building secure AI systems is ensuring that sensitive information doesn’t become part of the training data. Once a secret is ingested and learned by an AI model, it can be difficult or impossible to remove. This is where HCP Vault Radar plays a critical role.
Early detection: Finding secrets before they enter the pipeline
HCP Vault Radar continuously scans your entire development and data ecosystem, including:
- Code repositories
- Data repositories and storage buckets
- Shared folders and file systems
- Logs and documentation
Using advanced pattern recognition and heuristics, Vault Radar automatically detects secrets wherever they are hidden, whether accidentally committed in source code, embedded in training datasets, or lurking in configuration files.
Preventing secret leakage in AI training data
Integrating HCP Vault Radar within your machine learning operations (MLOps) pipelines helps you enforce data security at scale:
- Remediate exposure early: When HCP Vault Radar detects exposed secrets in code or datasets within your MLOps workflows, teams can promptly remove or redact them before data moves further in the pipeline. These secrets should then be imported into HashiCorp Vault for secure, centralized management, providing encrypted storage, fine-grained access controls, and detailed audit logging. Vault’s dynamic secrets and automated rotation capabilities help minimize exposure risks throughout the model lifecycle. Integrating these steps into your MLOps process creates a continuous feedback loop that enforces data hygiene and prevents secrets from re-entering training or deployment pipelines, ensuring secure and compliant AI operations.
- Enforce clean data policies: Vault Radar can be integrated into CI/CD workflows or data ingestion pipelines to automatically block datasets or code changes containing secrets from progressing downstream, preventing contaminated data from entering model training environments.
- Maintain training data hygiene: Continuous scanning ensures that only sanitized, secret-free data feeds into AI models, drastically reducing the risk that models memorize and leak sensitive information during inference.
Automated, scalable, and continuous protection
Given the massive scale and rapid iteration cycles in modern AI development, manual reviews for secrets detection are impractical and prone to human error. AI teams routinely process vast amounts of data at high velocity, making continuous, automated scanning essential to keep pace without slowing down innovation. HCP Vault Radar automates this process at scale, acting as a critical guardrail within the MLOps lifecycle. This automation ensures that secrets are caught early, before they can contaminate training data or model artifacts.
Real-world example: GitHub Copilot
One real-world example of secrets exposure in AI models is the case of GitHub Copilot. Copilot was trained on vast amounts of publicly available code. While this approach enabled the model to autocomplete code and accelerate development, it also revealed a critical vulnerability: it learned and reproduced secrets.
What happened?
Soon after its release, security researchers and developers discovered that GitHub Copilot could autocomplete sensitive credentials such as:
- AWS access keys
- API tokens
- Database connection strings
- Private keys and passwords
These secrets weren’t hard coded into the model manually, they were learned from training data, likely from open source repositories where developers had committed secrets in code. When prompted with certain patterns (e.g. AWS_ACCESS_KEY_ID=), Copilot would sometimes complete the line with what appeared to be real, valid-looking credentials.
What this means for AI practitioners?
If AI models are trained on unfiltered or unvetted data, whether from public repos, internal documentation, logs, or chat transcripts — the same risks apply. The Copilot example is a public case, but the same threat exists inside the enterprise:
- Secrets in internal codebases can be memorized by fine-tuned models.
- Sensitive keys in training data can reappear during inference.
- Once learned, these secrets are incredibly hard to scrub from the model's parameters.
- You may not even know the secret was leaked until it's surfaced in a prompt.
- These risks scale with model size and usage; the more users prompt the model, the higher the chance of a secret being surfaced.
To prevent similar risks in your organization:
- Scan training data before ingestion using tools like HCP Vault Radar to identify and remediate exposed secrets in source code, datasets, and documentation.
- Use HashiCorp Vault to centrally manage and inject secrets at runtime — keeping them out of code and config files entirely.
- Integrate secrets scanning into CI/CD and MLOps workflows, blocking contaminated data from being included in model training or fine-tuning.
- Anonymize sensitive training data with advanced data protection tools like Vault’s encryption as a service secrets engines. Read the example tutorials Protect data privacy in Amazon Bedrock with Vault and Anonymize RAG data in IBM Granite and Ollama using HCP Vault.
- Monitor inference logs to catch accidental leakage of sensitive values through model completions or chatbot conversations.
Key takeaway
The GitHub Copilot incident is a preview of what can go wrong when AI is trained without robust secrets hygiene. As AI becomes more embedded in business-critical systems, it’s imperative to treat secret scanning as a first-class citizen in your MLOps lifecycle.
Looking Ahead — Vault and Vault Radar together
As AI systems become more sophisticated and integrated into everyday workflows, new secrets management challenges continue to emerge. One notable concern is the persistent memory in chatbots and conversational AI. These models can inadvertently retain sensitive information shared during interactions, creating a novel risk vector for secret leakage during inference.
To address these evolving threats, the development of LLM-aware secret detection tools is gaining momentum. These products, like HCP Vault Radar, understand the unique nature of large language models — scanning both training corpora and live inference inputs for sensitive data in context, not just simple pattern matches.
Vault and HCP Vault Radar are uniquely positioned to help organizations meet these challenges head-on. Together, they form a powerful, end-to-end security solution that integrates seamlessly into AI pipelines:
- During data preparation and training: Vault Radar scans datasets and source code, ensuring secrets are removed before ingestion, while Vault manages secrets used in environment configuration and API calls securely.
- In fine-tuning and deployment: Vault enforces dynamic secret injection with strict access controls, and Vault Radar scans updates continuously to catch any accidental leaks.
- At inference: Vault Radar monitors live inputs and chat histories, detecting and alerting on potential secret exposure, while Vault secures any runtime secrets used by deployed models.
By embedding Vault and Vault Radar deeply into MLOps workflows, organizations can effectively prevent secrets from contaminating AI training and inference, maintain strict compliance, and foster a secure environment for AI innovation.
Secure your MLOps workflows by introducing Vault and Vault Radar. Signup for the Vault Radar free trial today.