How Lyft Uses ML to Make 100 Million Predictions A Day
Database Benchmarking for Performance: Virtual Masterclass (Sponsored)
Learn how to accurately measure database performance

Free 2-hour masterclass | June 18, 2025
This masterclass will show you how to design and execute meaningful tests that reflect real-world workload patterns. We’ll discuss proven strategies that help you rightsize your performance testing infrastructure, account for the impact of concurrency, recognize and mitigate coordinated omission, and understand probability distributions. We will also share ways to avoid common pitfalls when benchmarking high-performance databases.
After this free 2-hour masterclass, you will know how to:
Tune your query and traffic patterns based on your database and workload needs
Measure how warm-up phases, throttling, and internal database behaviors impact results
Correlate latency, throughput, and resource usage for actionable performance tuning
Report clear, reproducible benchmarking results
Disclaimer: The details in this post have been derived from the articles/videos shared online by the Lyft Engineering Team. All credit for the technical details goes to the Lyft Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Hundreds of millions of machine learning inferences power decisions at Lyft every day. These aren’t back-office batch jobs. They’re live, high-stakes predictions driving every corner of the experience from pricing a ride to flagging fraud, predicting ETAs to deciding which driver gets which incentive.
Each inference runs under pressure and a single-digit millisecond budget. This translates to millions of requests per second. Dozens of teams, each with different needs and models, are pushing updates on their schedules. The challenge is staying flexible without falling apart.
Real-time ML at scale breaks into two kinds of problems:
Data Plane pressure: Everything that happens in the hot path. This includes CPU and memory usage, network bottlenecks, inference latency, and throughput ceilings.
Control Plane complexity: This is everything around the model. Think of aspects like deployment and rollback, versioning, retraining, backward compatibility, experimentation, ownership, and isolation.
Early on, Lyft leaned on a shared monolithic service to serve ML models across the company. However, the monolith created more friction than flexibility. Teams couldn’t upgrade libraries independently. Deployments clashed and ownership blurred. Small changes in one model risked breaking another, and incident investigation turned into detective work.
The need was clear: build a serving platform that makes model deployment feel as natural as writing the model itself. It had to be fast, flexible, and team-friendly without hiding the messy realities of inference at scale.
In this article, we’ll look at how Lyft built an architecture to accomplish this requirement and the challenges they faced.
Architecture and System Components
LyftLearn Serving doesn’t reinvent the wheel. It slots neatly into the microservices foundation already powering the rest of Lyft. The goal wasn’t to build a bespoke ML serving engine from scratch. It was to extend proven infrastructure with just enough intelligence to handle real-time inference, without bloating the system or boxing teams.
At the core is a dedicated microservice: lightweight, composable, and self-contained. Each team runs its instance, backed by Lyft's service mesh and container orchestration stack. The result: fast deploys, predictable behavior, and clean ownership boundaries.
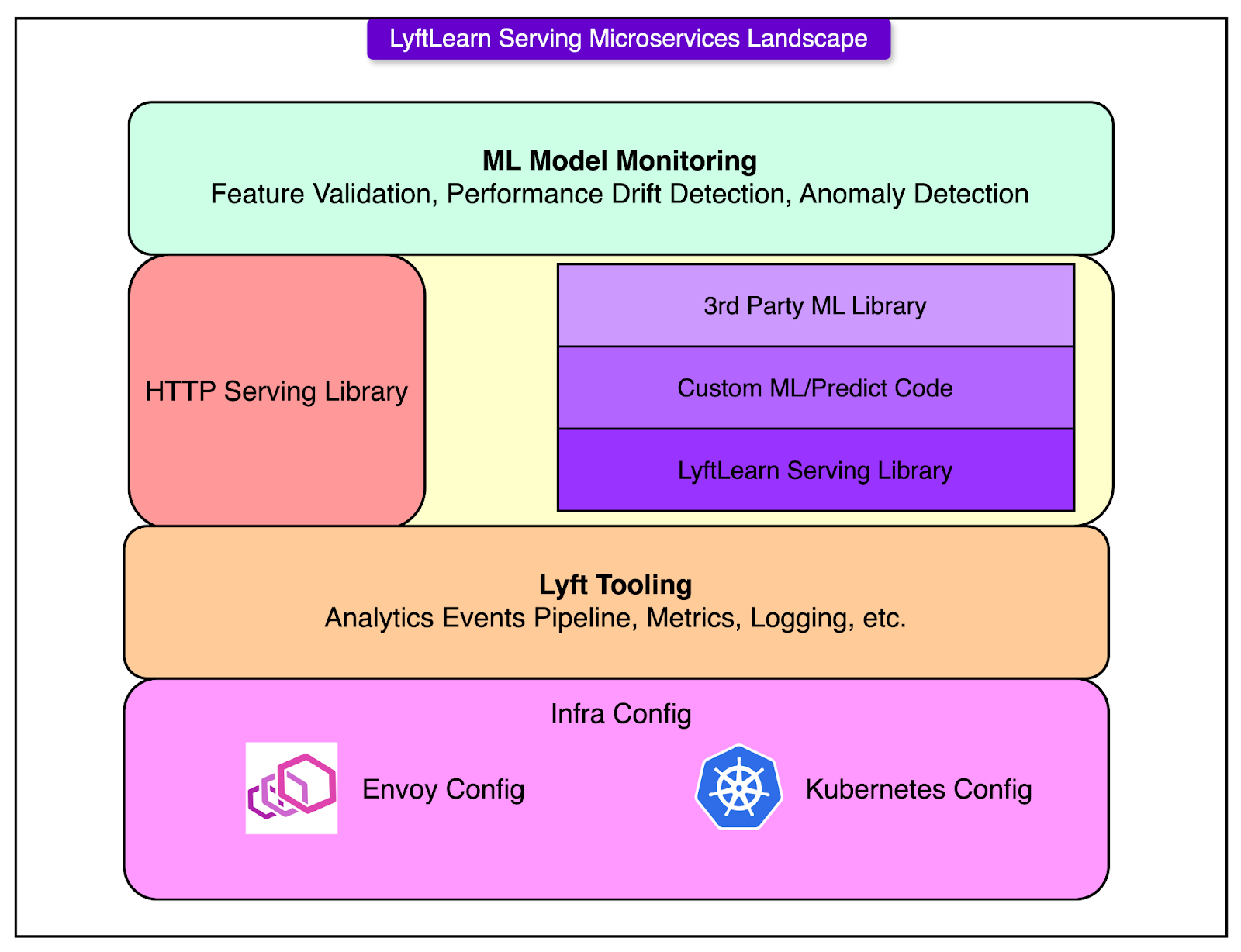
Let’s break down this architecture flow diagram:
HTTP Serving Layer
Every request to a LyftLearn Serving service hits an HTTP endpoint first. This interface is built using Flask, a minimalist Python web framework. While Flask alone wouldn’t scale to production workloads, it’s paired with Gunicorn, a pre-fork WSGI server designed for high concurrency.
To make this stack production-grade, Lyft optimized the setup to align with Envoy, the service mesh that sits in front of all internal microservices. These optimizations ensure:
Low tail latency under high request volume.
Smooth connection handling across Envoy-Gunicorn boundaries.
Resilience to transient network blips.
This layer keeps the HTTP interface thin and efficient, just enough to route requests and parse payloads.
Core Serving Library
This is where the real logic lives. The LyftLearn Serving library handles the heavy lifting:
Model loading and unloading: Dynamically brings models into memory from saved artifacts
Versioning: Tracks and manages different model versions cleanly
Shadowing: Enables safe testing by running inference on new models in parallel, without affecting live results
Monitoring and logging: Emits structured logs, metrics, and tracing for each inference request
Prediction logging: Captures outputs for later audit, analytics, or model debugging
This library is the common runtime used across all teams. It centralizes the “platform contract” so individual teams don’t need to re-implement the basics. But it doesn’t restrict customization.
Custom ML/Predict Code
The core library is dependency-injected with team-owned inference logic. Every team provides two Python functions:
def load(self, file: str) -> Any:
# Custom deserialization logic for the trained model
...
def predict(self, features: Any) -> Any:
# Custom inference logic using the loaded model
…
Source: Lyft Engineering Blog
This design keeps the platform flexible. A team can use any model structure, feature format, or business logic, as long as it adheres to the basic interface. This works because the predicted path is decoupled from the transport and orchestration layers.
Third-Party ML Library Support
LyftLearn Serving makes no assumptions about the ML framework. Whether the model uses TensorFlow, PyTorch, LightGBM, XGBoost, or a home-grown solution, it doesn’t matter.
As long as the model loads and predicts through Python, it’s compatible. This lets teams:
Upgrade to newer framework versions without coordination.
Use niche or experimental libraries.
Avoid vendor lock-in or rigid SDKs.
Framework choice becomes a modeler’s decision, not a platform constraint.
Integration with Lyft Infrastructure
The microservice integrates deeply with Lyft’s existing production stack:
Metrics and tracing plug into the company-wide observability pipeline.
Logs and prediction events feed into central analytics systems.
Kubernetes handles service orchestration and autoscaling.
Envoy service mesh provides secure, discoverable network communication.
This alignment avoids duplicating effort. Teams inherit baseline reliability, visibility, and security from the rest of Lyft’s infrastructure, without needing to configure it themselves.
Isolation and Ownership Principles
When dozens of teams deploy and serve ML models independently, shared infrastructure quickly becomes shared pain. One broken deploy can block five others. A single library upgrade triggers weeks of coordination and debugging turns into blame-shifting. That’s what LyftLearn Serving was built to avoid.
The foundation of its design is hard isolation by repository, not as a policy, but as a technical boundary enforced at every layer of the stack.
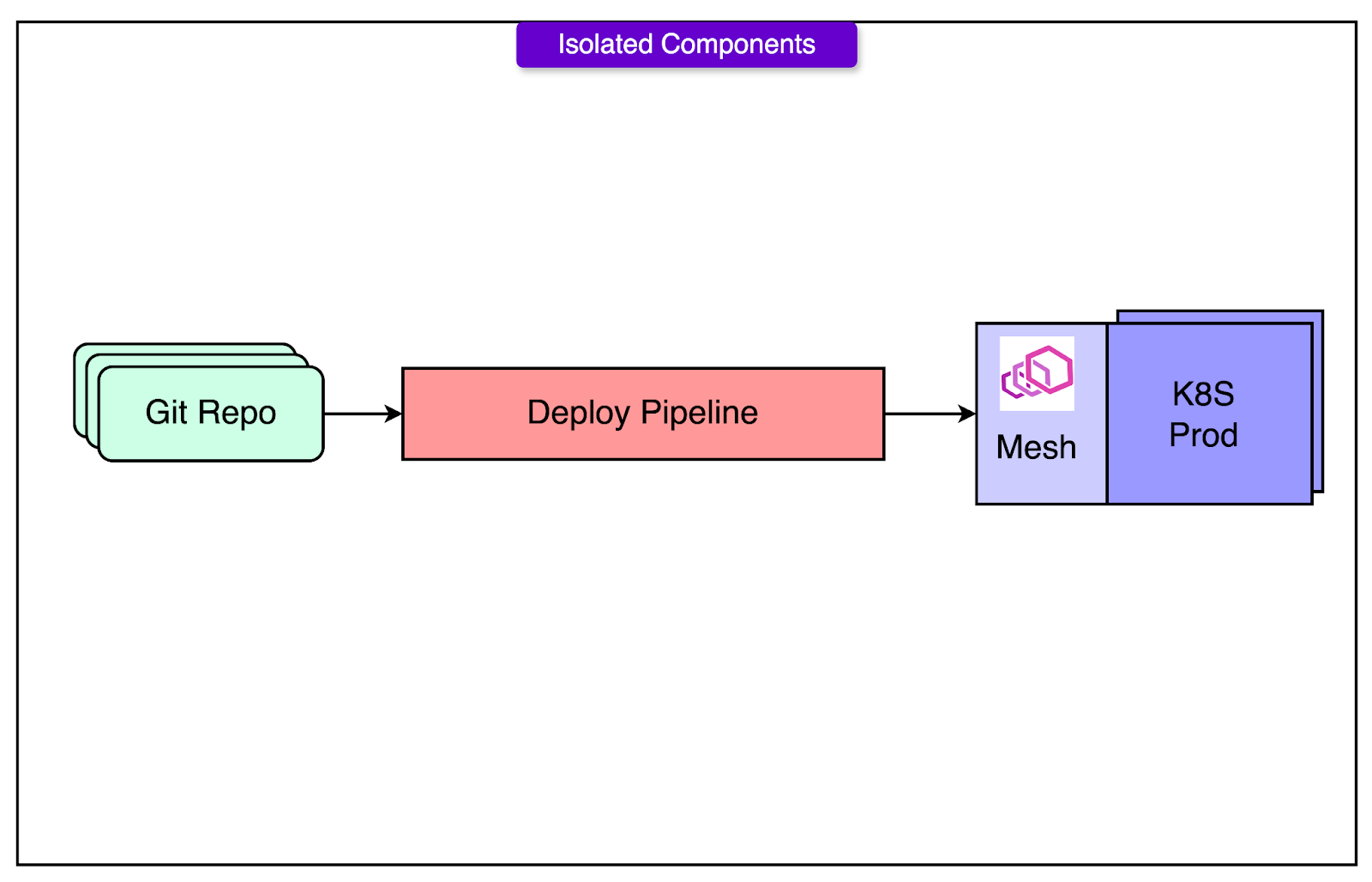
One Repo, One Service, One Owner
Every team using LyftLearn Serving gets its own GitHub repository. This repo isn’t just for code, but it defines the entire model-serving lifecycle:
The service code includes custom load() and predict() logic.
The configuration files for deployment and orchestration.
The integration hooks for CI/CD, monitoring, and metrics.
There’s no central repository to manage and no shared runtime to coordinate. If a team needs five models, they can choose to host them in one repo or split them across five.
Independent Deploy Pipelines
Each repo comes with its deploy pipeline, fully decoupled from others. This includes:
Staging and production environments.
CI jobs that run model self-tests and linting.
Version tagging and release promotion.
If one team pushes broken code, it doesn’t affect anyone else. If another needs to hotfix a bug, they can deploy instantly. Isolation removes the need for cross-team coordination during high-stakes production changes.
Runtime Isolation via Kubernetes and Envoy
LyftLearn Serving runs on top of Lyft’s Kubernetes and Envoy infrastructure. The platform assigns each team:
A dedicated namespace in the Envoy service mesh
Isolated Kubernetes resources (pods, services, config maps)
Customizable CPU, memory, and replica settings
Team-specific autoscaling and alerting configs
This ensures that runtime faults, whether it’s a memory leaks, high CPU usage, or bad deployment. A surge in traffic to one team’s model won’t starve resources for another. A crash in one container doesn’t bring down the serving infrastructure.
Tooling: Config Generator
Getting a model into production shouldn’t mean learning multiple configuration formats, wiring up runtime secrets, or debugging broken deploys caused by missing database entries.
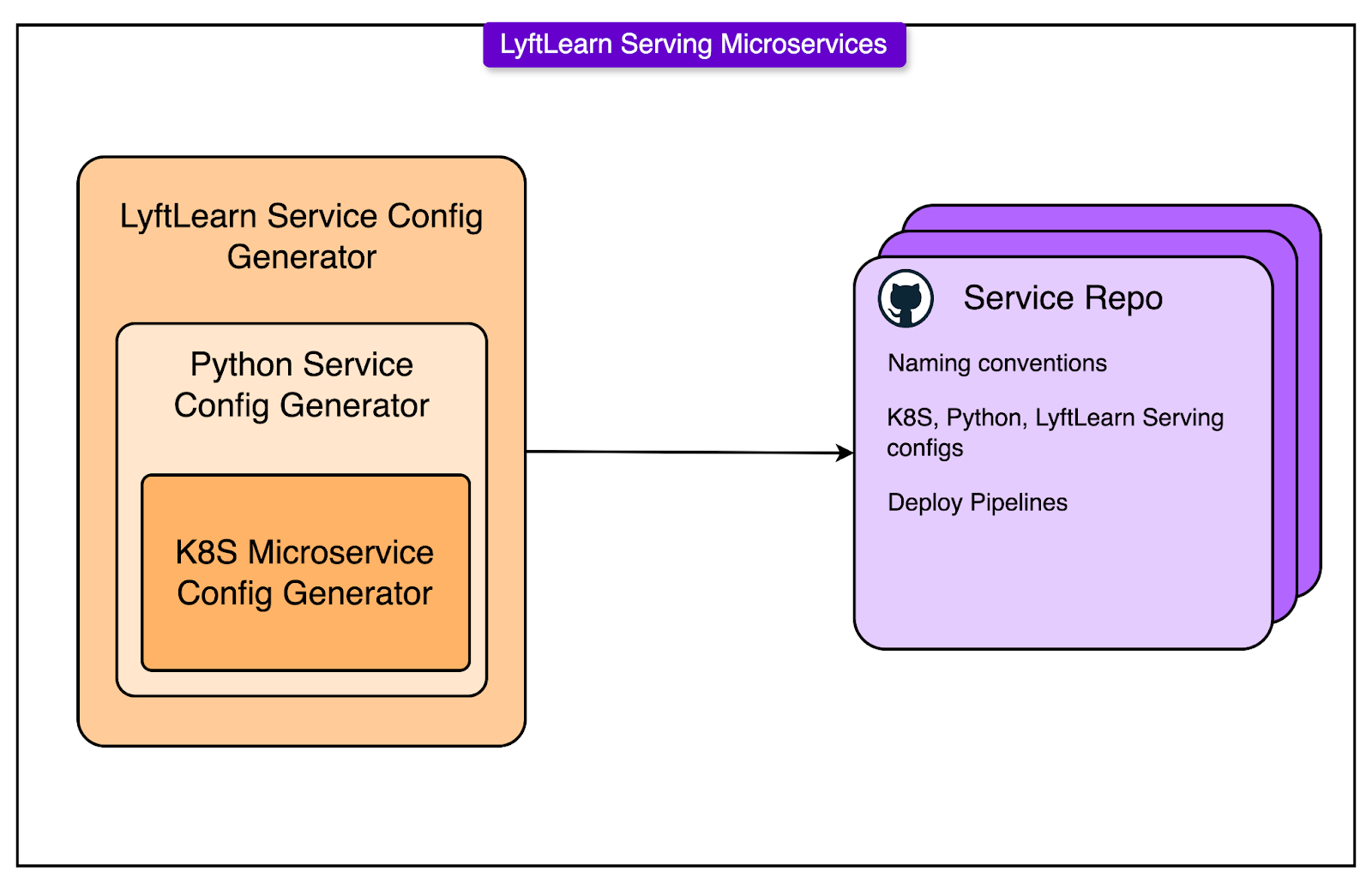
To streamline this, LyftLearn Serving includes a Config Generator: a bootstrapping tool that wires up everything needed to go from zero to a working ML serving microservice. Spinning up a new LyftLearn Serving instance involves stitching together pieces from across the infrastructure stack:
Terraform for provisioning cloud infrastructure.
YAML and Salt for Kubernetes and service mesh configuration.
Python is used for defining the serving interface.
Runtime secrets for secure credential access.
Database entries for model versioning or feature lookups.
Envoy mesh registration for service discovery.
Expecting every ML team to hand-craft this setup would be a recipe for drift, duplication, and onboarding delays. The config generator collapses that complexity into a few guided inputs.
The generator runs on Yeoman, a scaffolding framework commonly used for bootstrapping web projects, but customized here for Lyft’s internal systems.
A new team running the generator walks through a short interactive session:
Define the team name.
Specify the service namespace.
Choose optional integrations (for example, logging pipelines and model shadowing).
The tool then emits a fully-formed GitHub repo with:
Working example code for the load() and predict() functions.
Pre-wired deployment scripts and infrastructure configs.
Built-in test data scaffolds and CI setup.
Hooks into monitoring and observability.
Once the repo is generated and the code is committed, the team gets a functioning microservice, ready to accept models, run inference, and serve real traffic inside Lyft’s mesh. Teams can iterate on the model logic immediately, without first untangling infrastructure.
Model Self-Testing System
Model serving can often drift when a new dependency sneaks in, slightly changing output behavior. For example, a training script gets updated, but no one notices the prediction shift. Or, a container upgrade silently breaks deserialization. By the time someone spots the drop in performance, millions of bad inferences have already shipped.
To fight this, LyftLearn Serving introduces a built-in Model Self-Testing System. It’s a contract embedded inside the model itself, designed to verify behavior at the two points that matter most: before merge and after deploy.
Every model class defines a test_data property: structured sample inputs with expected outputs:
class SampleModel(TrainableModel):
@property
def test_data(self) -> pd.DataFrame:
return pd.DataFrame([
[[1, 0, 0], 1], # Input should predict close to 1
[[1, 1, 0], 1]
], columns=[“input”, “score”])Source: Lyft Engineering Blog
This isn’t a full dataset. It’s a minimal set of hand-picked examples that act as canaries. If a change breaks expected behavior on these inputs, something deeper is likely wrong. The test data travels with the model binary and becomes part of the serving lifecycle.
Two checkpoints that matter are as follows:
During Deployment Runtime
After a model loads inside a LyftLearn Serving instance, it immediately runs predictions on its test_data. The results:
Get logged and surfaced in metrics dashboards.
Trigger alerts if predictions drift too far from expected.
Provide an immediate signal of runtime integrity.
This catches subtle breakages caused by environment mismatches. For example, a model trained in Python 3.8 but deployed into a Python 3.10 container with incompatible dependencies.
During Pull Requests
When a developer opens a PR in the model repo, CI kicks in. It performs the following activities:
Loads the new model artifacts.
Runs predictions on the stored test_data.
Compares outputs against previously known-good results.
If the outputs shift beyond an acceptable delta, the PR fails, even if the code compiles and the service builds cleanly. The diagram below shows a typical development flow:
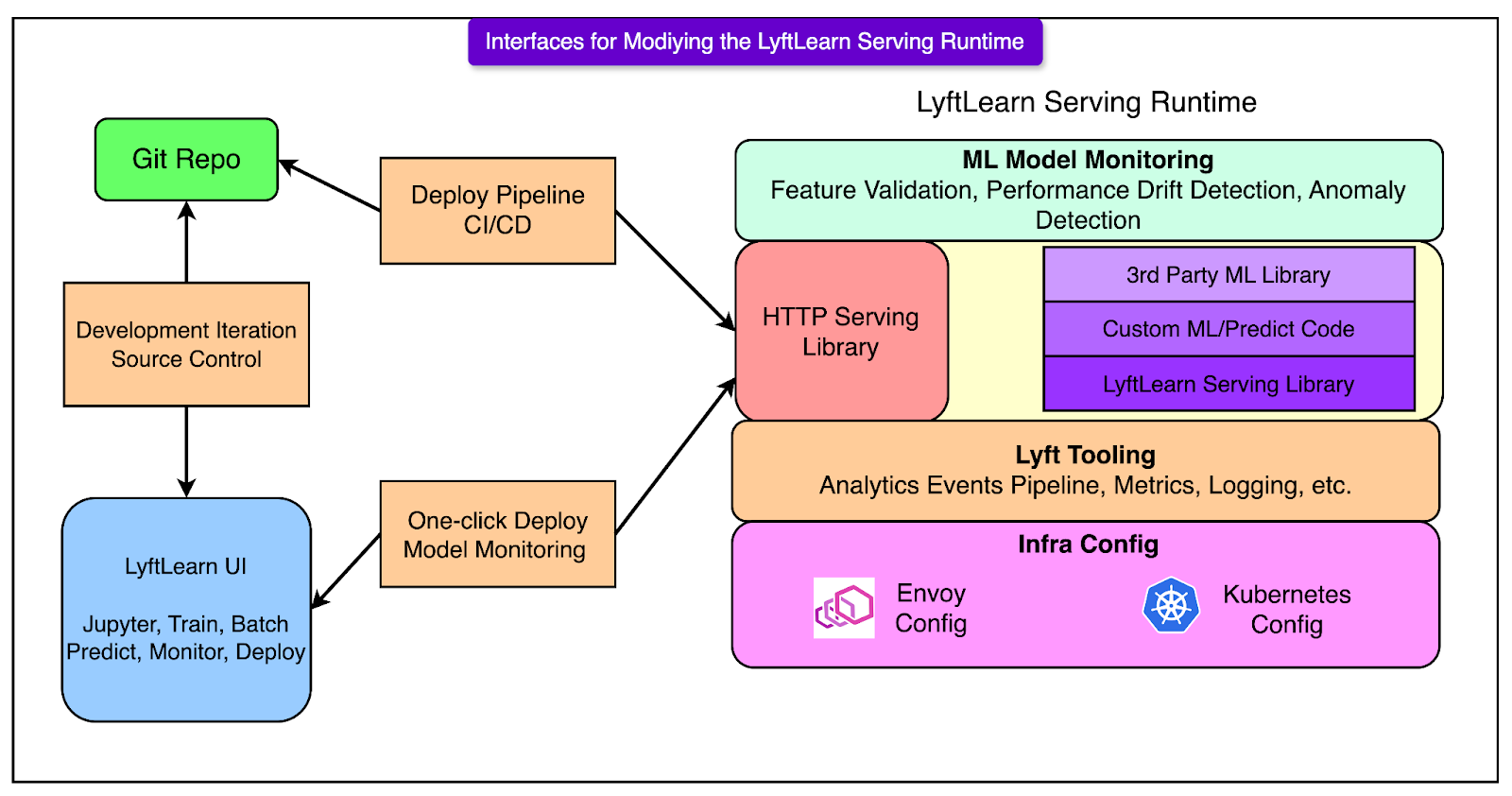
Inference Request Lifecycle
A real-time inference system lives in the milliseconds between an HTTP request and a JSON response. That tiny window holds a lot more than model math. It’s where routing, validation, prediction, logging, and monitoring converge.
LyftLearn Serving keeps the inference path slim but structured. Every request follows a predictable, hardened lifecycle that allows flexibility without sacrificing control.
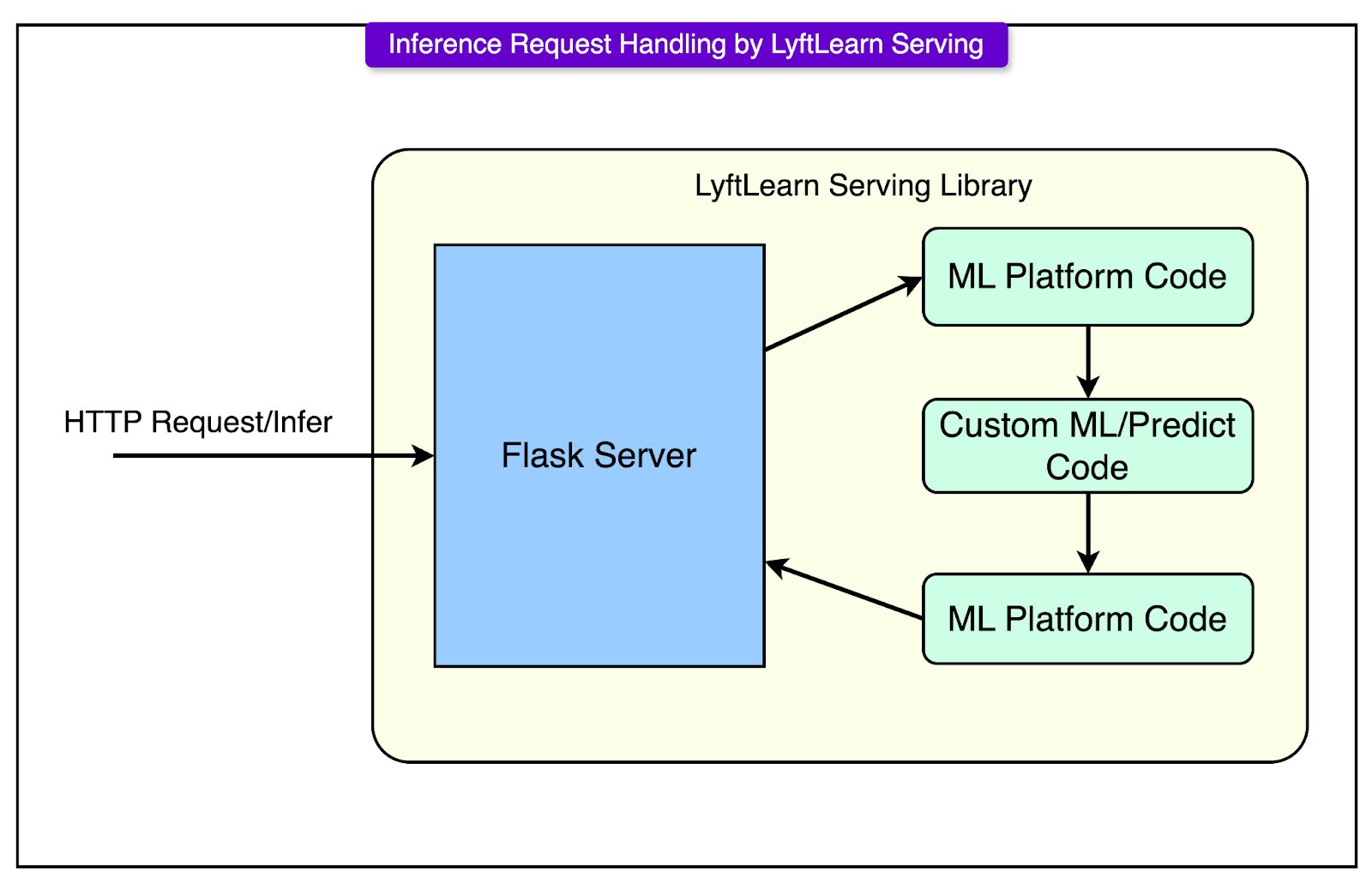
Here’s a step-by-step on how the request gets served:
Request hits the Flask endpoint: The service exposes an /infer route via Flask, backed by Gunicorn workers. Envoy handles the upstream routing. The incoming payload is parsed and handed off to the core serving library.
The core library retrieves the model: Using the model_id, the runtime looks up the corresponding model. If the model isn’t already loaded into memory, the system calls the team-supplied load() function and loads it on demand. This is where versioning logic, caching, and model lifecycle controls kick in. There’s no global registry and no shared memory. Each service owns and manages its models.
Input validation and preprocessing: Before running inference, the platform performs sanity checks on the features object, such as type or shape validation, required field presence, and optional model-specific hooks. This step guards against malformed inputs and prevents undefined behavior in downstream logic.
User-defined predict() runs the inference: Once the inputs are deemed valid, the system hands control to the custom predict() function written by the modeler. This function converts inputs into the expected format and calls the underlying ML framework (for example, LightGBM, TensorFlow) to return the prediction output. The predict() function is hot-path code. It runs millions of times per day. Its performance and correctness directly affect latency and downstream decisions.
Logs, metrics, and analytics: After the output is generated, the platform automatically logs the request and response for debugging and audit trails. It also emits latency, throughput, and error rate metrics and triggers analytics events that flow into dashboards or real-time monitoring. This observability layer ensures every inference can be traced and every service behavior can be measured.
Response returned to the caller: Finally, the result is packaged into a JSON response and returned via Flask. From request to response, the entire path is optimized for speed, traceability, and safety.
Conclusion
Serving machine learning models in real time isn’t just about throughput or latency. It’s about creating systems that teams can trust, evolve, and debug without friction.
LyftLearn Serving didn’t emerge from a clean slate or greenfield design. It was built under pressure to scale, to isolate, and to keep dozens of teams moving fast without stepping on each other’s toes.
Several lessons surfaced along the way, and they’re worth understanding:
“Model” means different things to different people. A serialized object, a training script, and a prediction endpoint all fall under the same label. Without clear definitions across tooling and teams, confusion spreads fast.
Documentation is part of the product. If teams can’t onboard, debug, or extend without asking the platform team, the system doesn’t scale. LyftLearn Serving treats docs as first-class citizens.
Once a model is deployed behind an API, someone, somewhere, will keep calling it. Therefore, stability is a requirement for any serving system that expects to live in production.
Trade-offs aren’t optional. Seamless UX conflicts with flexible composability. Structured pipelines clash with custom workflows. Every decision makes something easier and something else harder. The trick is knowing who the system is really for and being honest about what’s being optimized.
Power users shape the platform. Build for the most advanced, most demanding teams first. If the platform meets their needs, it’ll likely meet everyone else’s. If not, it won’t scale past the first few adopters.
Prefer boring tech when it works. Stability, debuggability, and operational maturity are key aspects to consider.
LyftLearn Serving is still evolving, but its foundations hold. It doesn’t try to hide complexity, but it isolates it. Also, it enforces a contract around how the models behave in production.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing [email protected].