How Halo on Xbox Scaled to 10+ Million Players using the Saga Pattern
The 6 Core Competencies of Mature DevSecOps Orgs (Sponsored)

Understand the core competencies that define mature DevSecOps organizations. This whitepaper offers a clear framework to assess your organization's current capabilities, define where you want to be, and outline practical steps to advance in your journey. Evaluate and strengthen your DevSecOps practices with Datadog's maturity model.
Disclaimer: The details in this post have been derived from the articles/videos shared online by the Halo engineering team. All credit for the technical details goes to the Halo/343 Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
In today's world of massive-scale applications, whether it’s gaming, social media, or online shopping, building reliable systems is a difficult task. As applications grow, they often move from using a single centralized database to being spread across many smaller services and storage systems. This change, while necessary for handling more users and data, brings a whole new set of challenges, especially around consistency and transaction handling.
In traditional systems, if we wanted to update multiple pieces of data (say, saving a new customer order and reducing inventory), we could easily rely on a transaction. A transaction would guarantee that either all updates succeed together or none of them happen at all.
However, in distributed systems, there is no longer just one database to talk to. We might have different services, each managing its data in different locations. Each one might be running on different servers, cloud providers, or even different continents. Suddenly, getting all of them to agree at the same time becomes much harder. Network failures, service crashes, and inconsistencies are now of everyday situations.
This creates a huge problem: how do we maintain correct and reliable behavior when we can't rely on traditional transactions anymore? If we’re booking a trip, we don’t want to end up with a hotel reservation but no flight. If we’re updating a player's stats in a game, we can't afford for some stats to update and others to disappear.
Engineers must find new ways to coordinate operations across multiple independent systems to tackle these issues. One powerful pattern for solving this problem is the Saga Pattern, a technique originally proposed in the late 1980s but increasingly relevant today. In this article, we’ll look at how the Halo Engineering Team at 343 Game Studio (now Halo Studios) used the Saga pattern to improve the player experience.
Build AI products and grow your impact (Sponsored)
Two critical themes define today's engineering landscape: building AI applications and growing your influence in an increasingly automated world. So, we teamed up with Maven to curate 6 hands-on courses on these topics, led by experienced practitioners.
Building Agentic AI Applications with Aishwarya Reganti (AWS)
Multi-Agent Applications with Amir Feizpour (AI engineer)
AI Evals with Hamel Husain (AI engineer, ex-Github, Airbnb)
Break Through to Executive with Ethan Evans (Amazon VP)
Elite Product Leadership with Amit Fulay (Microsoft VP)
Eng Management System with Gilad Naor (ex-Meta, Amazon)
Our friends at Maven said to use code BYTEBYTEGO to get $100 off any of these selected courses.
ACID Transactions
When engineers design systems that store and update data, they often rely on a set of guarantees called ACID properties. These properties make sure that when something changes in the system, like saving a purchase or updating a player's stats, it happens safely and predictably.
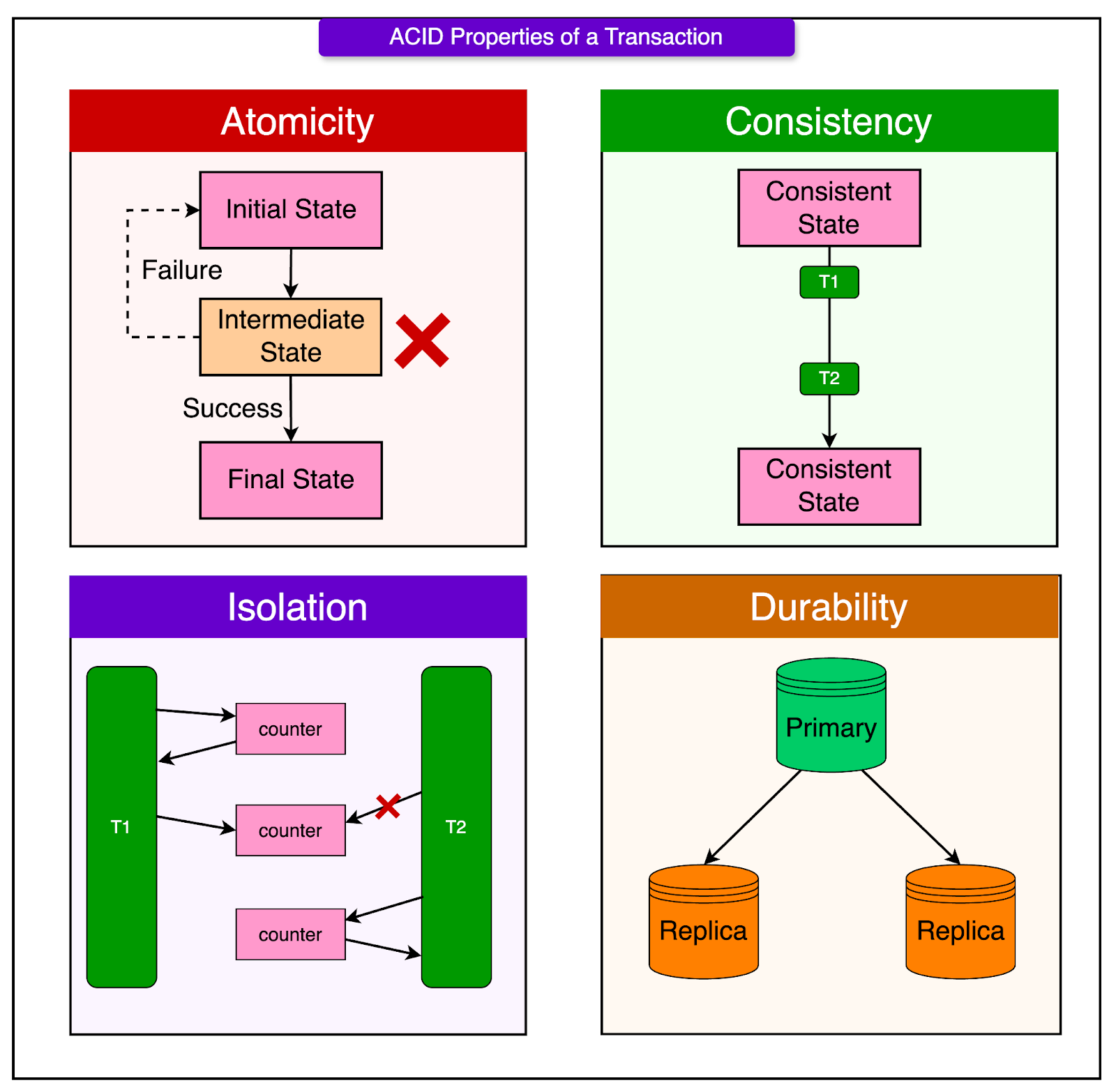
Here’s a quick look at each property.
Atomicity: Atomicity means "all or nothing". Either every step of a transaction happens successfully, or none of it does. If something goes wrong halfway, the system cancels everything so that it is not stuck with half-completed work. For example, either book both a flight and a hotel together, or neither.
Consistency: Consistency guarantees that the system’s data moves from one valid state to another valid state. After a transaction finishes, the data must still follow all the rules and constraints it’s supposed to. For example, after buying a ticket, the system shouldn’t show negative seat availability. The rules about what’s valid are always respected.
Isolation: Isolation ensures that transactions don’t interfere with each other even if they happen at the same time. It should feel like each transaction happens one after another, even when they’re happening in parallel. For example, if two people are trying to buy the last ticket at the same time, only one transaction succeeds.
Durability: Durability means that once a transaction is committed, it’s permanent. Even if the system crashes right after, the result stays safe and won't be lost. For example, if a user bought a ticket and the app crashes immediately after, the ticket is still booked and not lost in the system.
Single Database Model
In older system architectures, the typical way to build applications was to have a single, large SQL database that acted as the central source of truth.

Every part of the application, whether it was a game like Halo, an e-commerce site, or a banking app, would send all of its data to this one place.
Here’s how it worked:
Applications (like a game server or a website) would talk to a stateless service.
That stateless service would then communicate directly with the single SQL database.
The database would store everything: player statistics, game progress, inventory, financial transactions, all in one consistent, centralized location.
Some advantages of the single database model were strong guarantees enforced by the ACID properties, simplicity of development, and vertical scaling.
Scalability Crisis of Halo 4
During the development of Halo 4, the engineering team faced unprecedented scale challenges that had not been encountered in earlier titles of the franchise.
Halo 4 experienced an overwhelming level of engagement:
Over 1.5 billion games were played.
More than 11.6 million unique players connected and competed online.
Every match generated detailed telemetry data for each player: kills, assists, deaths, weapon usage, medals, and various other game-related statistics. This information needed to be ingested, processed, stored, and made accessible across multiple services, both for real-time feedback in the game itself and for external analytics platforms like Halo Waypoint.
The complexity further increased because a single match could involve anywhere from 1 to 32 players. For each game session, statistics needed to be reliably updated across multiple player records simultaneously, preserving data accuracy and consistency.
Inadequacy of a Single SQL Database
Before Halo 4, earlier installments in the series relied heavily on a centralized database model.
A single large SQL Server instance operated as the canonical source of truth. Application services would interact with this centralized database to read and write all gameplay, player, and match data, relying on the built-in ACID guarantees to ensure data integrity.
However, the scale required by Halo 4 quickly revealed serious limitations in this model:
Vertical Scaling Limits: While the centralized database could be scaled vertically (by adding more powerful hardware), there were inherent physical and operational limits. Beyond a certain threshold, no amount of memory, CPU power, or storage optimization could compensate for the growing volume of concurrent reads and writes.
Single Point of Failure: Relying on one database instance introduced a critical operational risk. Any downtime, data corruption, or resource saturation in that instance could bring down essential services for the entire player base.
Contention and Locking Issues: With millions of users interacting with the database simultaneously, contention for locks and indexes became a bottleneck.
Operational Complexity of Partitioning: The original centralized system was not designed for partitioned workloads. Retroactively introducing sharding or partitioning into a monolithic SQL structure would have required major rewrites and complex operational procedures, creating risks of inconsistency and service instability.
Mismatch with Cloud-native Architecture: Halo 4’s backend migrated to Azure’s cloud infrastructure, specifically using Azure Table Storage. Azure Table Storage is a NoSQL system that inherently relies on partitioned storage and offers eventual consistency. The old model of transactional consistency across a single database did not align with this partitioned, distributed environment.
Given these challenges, the engineering team recognized that continuing to rely on a monolithic SQL database would limit scalability and expose the system to unacceptable levels of risk and downtime. A transition to a distributed architecture was necessary.
Introduction to Saga Pattern
The Saga Pattern originated through a research paper published in 1987 by Hector Garcia-Molina and Kenneth Salem at Princeton University. The research addressed a critical problem: how to handle long-lived transactions in database systems.
At the time, traditional transactions were designed to be short-lived operations, locking resources for a minimal duration to maintain ACID guarantees. However, some operations, such as generating a complex bank statement, processing large historical datasets, or reconciling multi-step financial workflows, require holding locks for extended periods. These long-running transactions created bottlenecks by tying up resources, reducing system concurrency, and increasing the risk of failure.
The Saga Pattern solves these issues in the following ways:
A single logical operation is split into a sequence of smaller sub-transactions.
Each sub-transaction is executed independently and commits its changes immediately.
If all sub-transactions succeed, the Saga as a whole is considered successful.
If any sub-transaction fails, compensating transactions are executed in reverse order to undo the changes of previously completed sub-transactions.
See the diagram below that shows an example of this pattern:
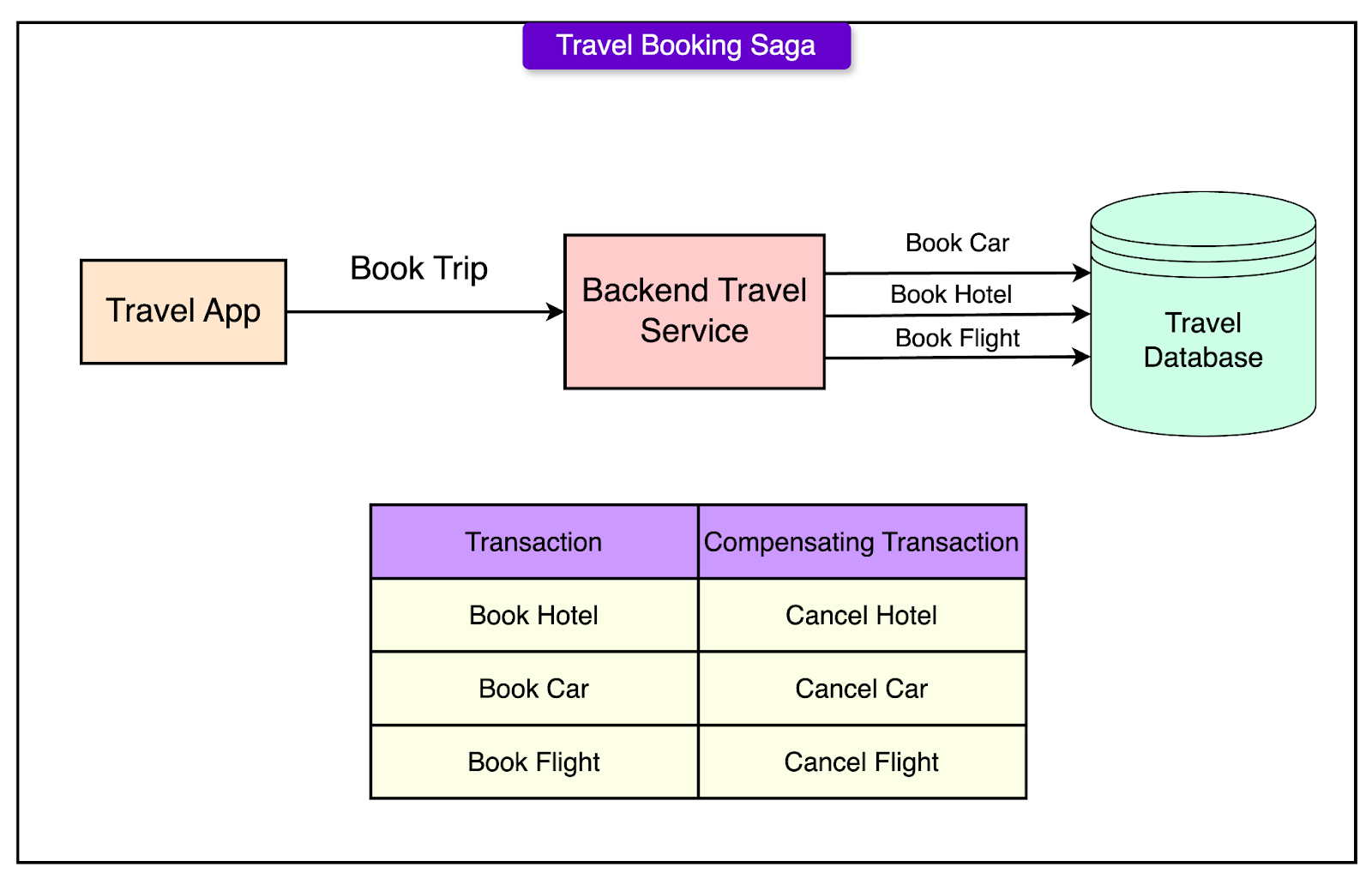
Key technical points about Sagas are as follows:
Sub-transactions must be independent: The successful execution of one sub-transaction should not directly depend on the outcome of another. This independence allows for better concurrency and avoids cascading failures.
Compensating transactions are required: For every sub-transaction, a corresponding compensating action must be defined. These compensating transactions semantically "undo" the effect of their associated operations. However, the system may not always be able to return to the exact previous state; instead, it aims for a semantically consistent recovery.
Atomicity is weakened: Unlike traditional transactions, where partial updates are never visible, in a Saga, intermediate states are visible to other parts of the system. Partial results may exist temporarily until either the full sequence completes or a failure triggers rollback through compensation.
Consistency is preserved through business logic: Instead of relying on database-level transactional guarantees, Sagas maintain application-level consistency by ensuring that after all sub-transactions and compensations, the system is left in a valid and coherent state.
Failure management is built in: Sagas treat failures as an expected part of the system's operation. The pattern provides a structured way to handle errors and maintain resilience without assuming perfect reliability.
Saga Execution Models
The main aspects of the Saga execution model are as follows:
Single Database Execution
When the Saga Pattern was first introduced, it was designed to operate within a single database system. In this environment, executing a saga requires two main components:
1 - Saga Execution Coordinator (SEC)
The Saga Execution Coordinator is a process that orchestrates the execution of all the sub-transactions in the correct sequence. It is responsible for:
Starting the saga
Executing each sub-transaction one after another
Monitoring the success or failure of each sub-transaction
Triggering compensating transactions if something goes wrong
The SEC ensures that the saga progresses correctly without needing distributed coordination because everything is happening within the same database system.
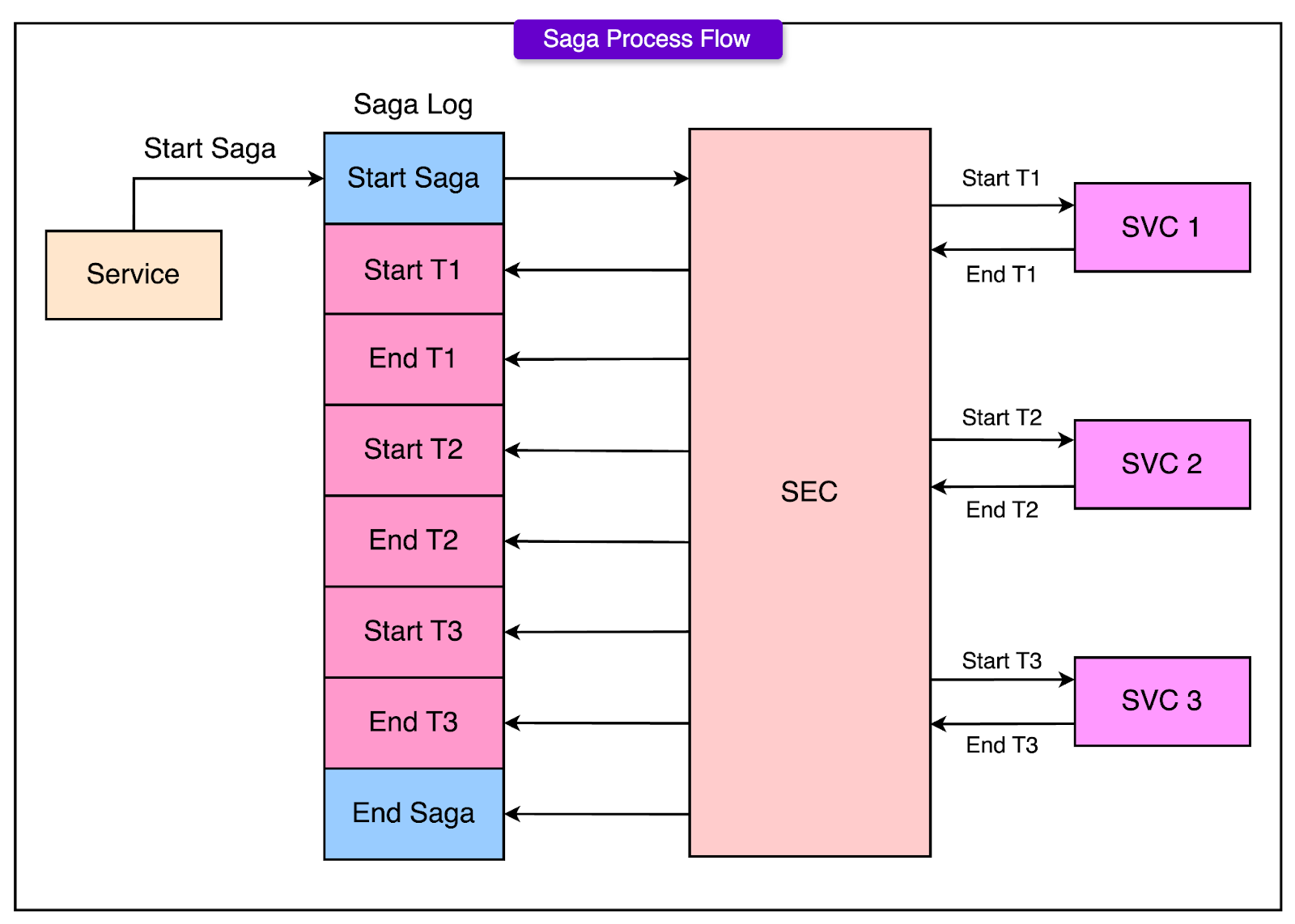
2 - Saga Log
The Saga Log acts as a durable record of everything that happens during the execution of a saga. Every major event, starting a saga, beginning a sub-transaction, completing a sub-transaction, beginning a compensating transaction, completing a compensating transaction, ending a saga, is written to the log.
The Saga Log guarantees that even if the SEC crashes during execution, the system can recover by replaying the events recorded in the log. This provides durability and recovery without relying on traditional transaction locking across the entire saga.
Failure Handling
Handling failures in a single database saga relies on a strategy called backward recovery.
This means that if any sub-transaction fails during the saga’s execution, the system must roll back by executing compensating transactions for all the sub-transactions that had already completed successfully.
Here’s how the process works:
Detection of Failure: The SEC detects that a sub-transaction has failed because the database operation either returns an error or violates a business rule.
Recording the Abort: The SEC writes an abort event to the Saga Log, marking that the forward execution path has been abandoned.
Starting Compensations: The SEC reads the Saga Log to determine which sub-transactions had been completed. It then begins executing the corresponding compensating transactions in the reverse order.
Completing Rollback: Each compensating transaction is logged in the Saga Log as it begins and completes.
After all necessary compensations have been successfully applied, the saga is formally marked as aborted in the log.
Halo 4 Stats Service
Here are the key components of how Halo used the Saga Pattern:
Service Architecture
The Halo 4 statistics service was built to handle large volumes of player data generated during and after every game. The architecture used a combination of cloud-based storage and actor-based programming models to manage this complexity effectively.
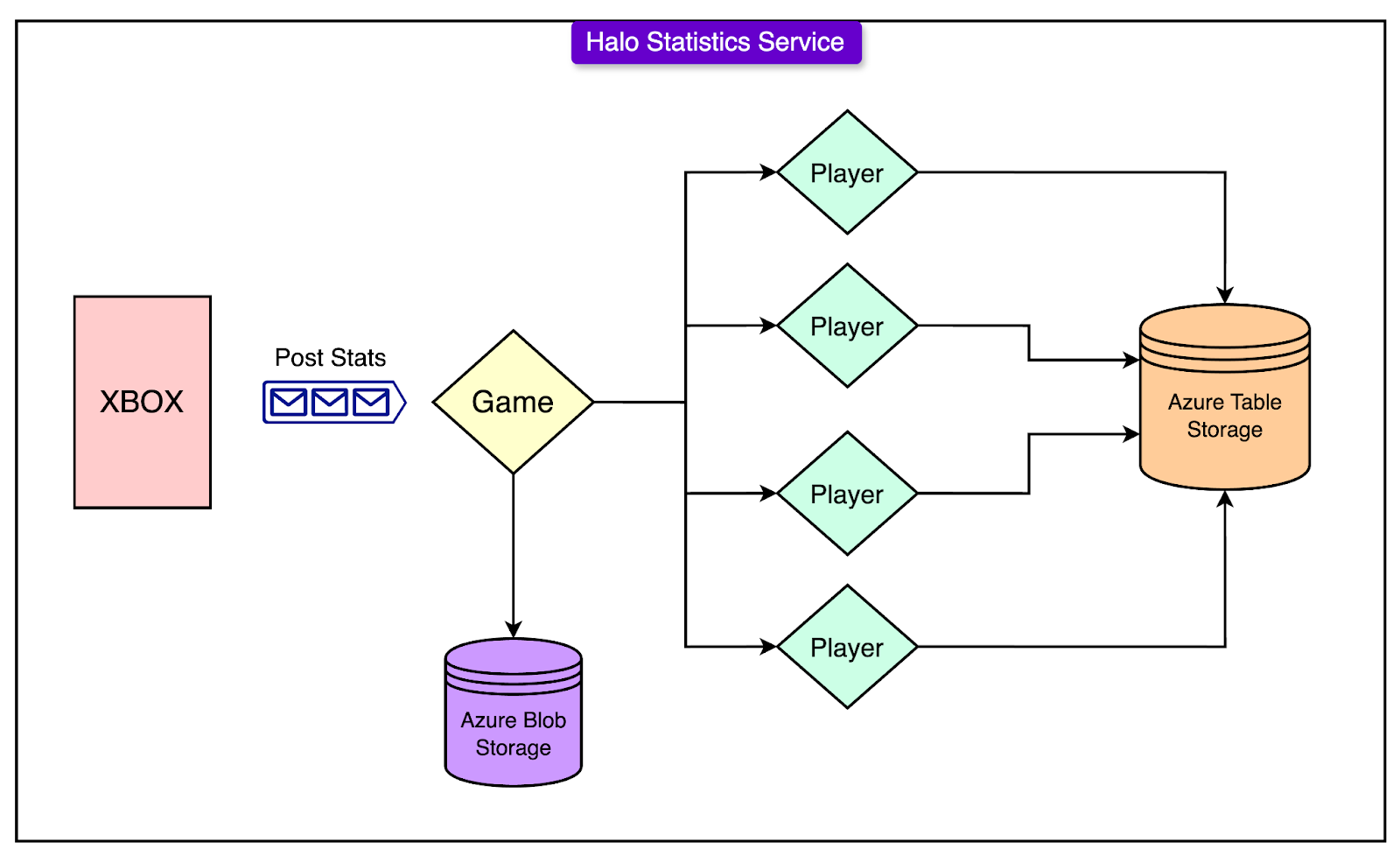
The service architecture included the following major components:
Azure Table Storage: All persistent player data was stored in Azure Table Storage, a NoSQL key-value store. Each player's data was assigned to a separate partition, allowing for highly parallel reads and writes without a single centralized bottleneck.
Orleans Actor Model: The team adopted Microsoft's Orleans framework, which is based on the actor model. Actors (referred to as "grains" in Orleans) represented different logical units in the system.
Game Grains handled the aggregation of statistics for a game session.
Player Grains were responsible for persisting each player’s statistics. In Halo 4’s backend system, a Player Grain is a logical unit that represents a single player’s data and behavior inside the server-side application.
Azure Service Bus: Azure Service Bus was used as a message queue and a distributed, durable log. When a new game is completed, a message containing the statistics payload is published to the Service Bus. This acted as the start of a saga.
Stateless Frontend Services: These services accepted raw statistics from Xbox clients, published them to the Service Bus, and triggered the saga processing pipelines.
The separation into game and player grains, combined with distributed cloud storage, provided a scalable foundation that could process thousands of simultaneous games and millions of concurrent player updates.
Saga Application
The team applied the Saga Pattern to manage the complex updates needed for player statistics across multiple partitions.
The typical sequence was:
Aggregation: After a game session ended, the Game Grain aggregated statistics from the participating players.
Saga Initiation: A message was logged in the Azure Service Bus indicating the start of a saga for updating statistics for that game.
Sub-requests to Player Grains: For each player in the game (up to 32), the Game Grain sent individual update requests to their corresponding Player Grains. Each Player Grain then updated its player's statistics in Azure Table Storage.
Logging Progress: Successful updates and any errors were recorded through the durable messaging system, ensuring that no state was lost even if a process crashed.
Completion or Failure: If all player updates succeeded, the saga was considered complete. If any player update failed (for example, due to a temporary Azure storage issue), the saga would not be rolled back but would move into a forward recovery phase.
Through this structure, the team could ensure that updates were processed independently per player without relying on traditional ACID transactions across all player partitions.
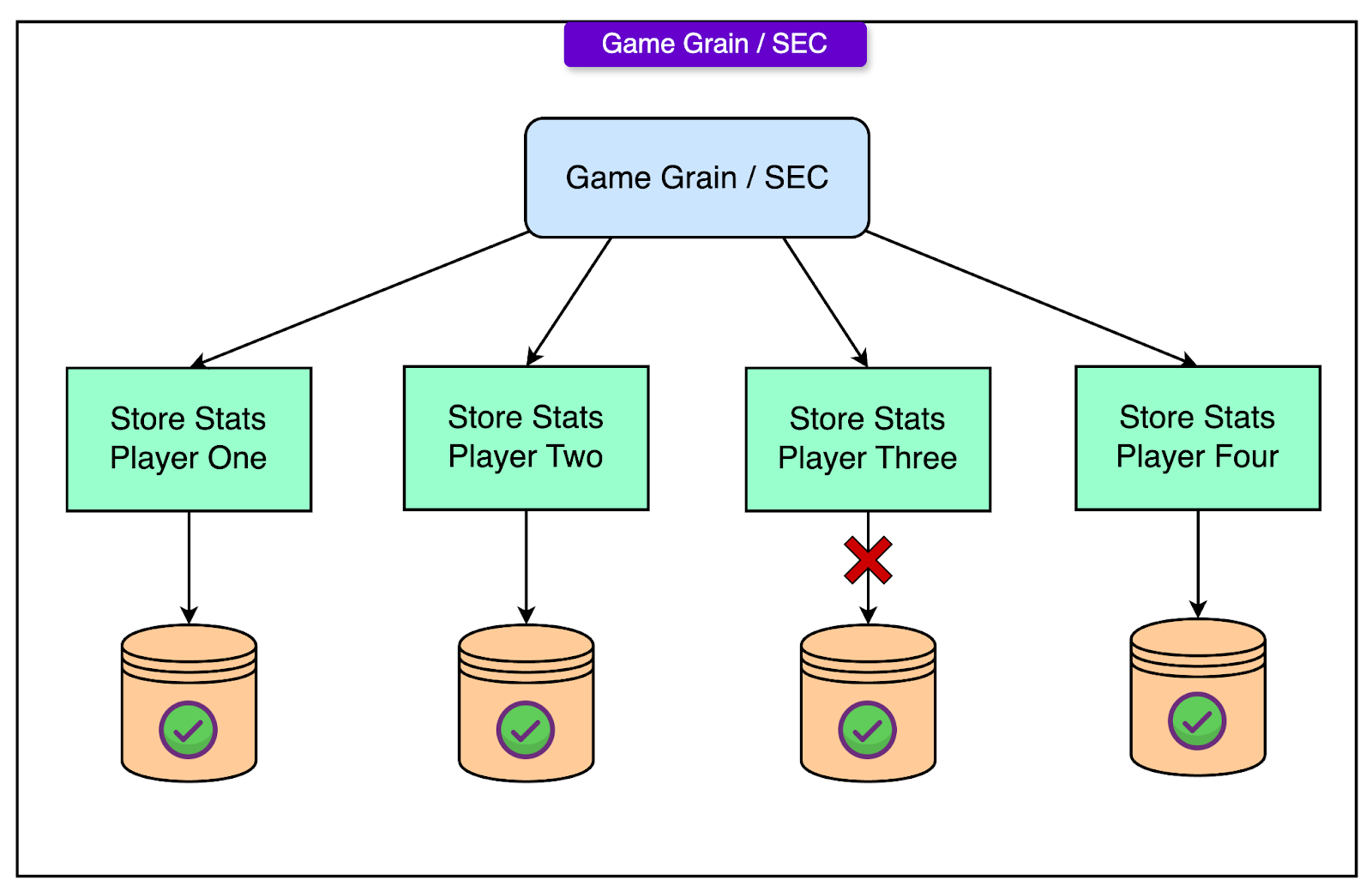
Forward Recovery Strategy
Rather than using traditional backward recovery (rolling back completed sub-transactions), the Halo 4 team implemented forward recovery for their statistics sagas.
The main reasons for choosing forward recovery are as follows:
User Experience: Players who had their stats updated successfully should not see those stats suddenly disappear if a rollback occurred. Rolling back visible, successfully processed data would create a confusing and poor experience.
Operational Efficiency: Retrying only the failed player updates was more efficient than undoing successful writes and restarting the entire game processing.
Here’s how forward recovery works:
If a Player Grain failed to update its statistics (for example, due to storage partition unavailability or quota exhaustion), the system recorded the failure but did not undo any successful updates already completed for other players.
The failed update was queued for a retry using a back-off strategy. This allowed time for temporary issues to resolve without overwhelming the storage system with aggressive retries.
Retried updates were required to be idempotent. That is, repeating the update operation would not result in duplicated statistics or corruption. This was achieved by relying on database operations that safely applied incremental changes or overwrote fields as necessary.
Successful retries eventually brought all player records to a consistent state, even if it took minutes or hours to do so after the original game session ended.
By using forward recovery and designing for idempotency, the Halo 4 backend was able to achieve high availability.
Conclusion
As systems grow to support millions of users, traditional database models that rely on centralized transactions and strong ACID guarantees begin to break down.
The Halo 4 engineering team’s experience highlighted the urgent need for a new approach: one that could handle enormous scale, tolerate failures gracefully, and still maintain consistency across distributed data stores.
The Saga Pattern provided an elegant and practical solution to these challenges. By decomposing long-lived operations into sequences of sub-transactions and compensating actions, the team was able to build a system that prioritized availability, resilience, and operational correctness without relying on expensive distributed locking or rigid coordination protocols.
The lessons learned from this system apply broadly, not only to gaming infrastructure but to any domain where distributed operations must maintain reliability at massive scale.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing [email protected].