Database Indexing Demystified: Index Types and Use-Cases
When query performance degrades, most engineers tend to reach for the application code first to identify issues.
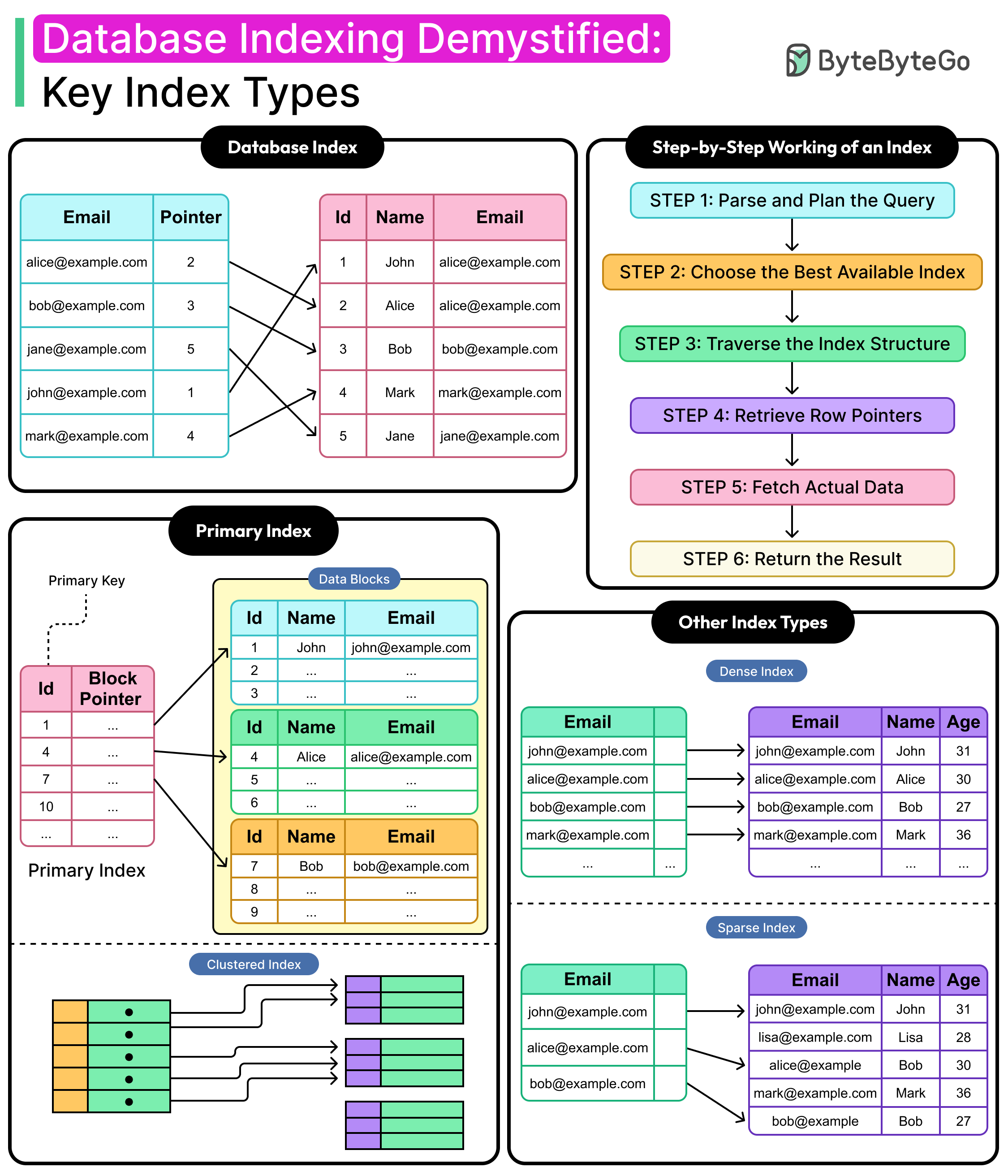
However, the root cause can also reside closer to the data at the storage level, and indexing could be the difference between a targeted lookup and a blind table scan that negatively impacts performance. With the right index in place, a query that once sifted through millions of rows can return results in milliseconds.
As datasets grow, the cost of scanning becomes untenable. Databases store data in pages, rows, and blocks, which are not optimized for arbitrary reads. Without indexes, every query that filters or sorts must inspect more rows than necessary. Multiply that overhead by thousands of queries per second, and systems start to buckle under I/O pressure.
Indexing solves this by narrowing the search space. Instead of traversing the entire table, the database engine uses a precomputed structure to jump closer to the target, much like flipping straight to the index of a book instead of reading every page.
But not all index types behave the same way. Some are built for fast key lookups. Others optimize range scans. Some improve performance for specific queries while adding overhead elsewhere.
In this article, we will explore the basic concept of database indexing and different index types. We will also understand what each index type does, when it helps, and what it costs.